首屏优化
背景
公司的产品面向的是企业用户,大部分企业用户会选择对产品进行私有化部署。
企业对产品的需求是差异化的,因此公司研发了一套低码平台方便客户对产品进行差异化定制。
客户通过低码平台的定制会产生JS文件,这些JS文件会在运行时加载。

大量客户反馈首屏等待时间过长的问题,需要制定针对性的优化策略解决问题。
而要针对性的优化必须要先弄清楚目前的性能热点在哪里,因此,我们将整个优化过程分为三步:
- 问题的收集与分析
- 措施的制定与实施
- 方案的部署与反馈
以上三步可反复轮询,直到问题解决。
问题的收集与分析
这一步的目标是要准确的找到客户侧的问题究竟在哪,找不到问题就无法针对性的制定优化措施。
而要找到问题并不容易,根据过往经验,大系统的优化问题定位往往需要几个环节的反复进行。

可是问题发生在客户侧,而客户侧的系统不直接暴露到公网,因此收集问题的环节就非常麻烦。
因此,我们搭建了一套客户侧数据上报的流程,让客户可以安全的把性能数据推送到我们的数据中心。

制定这套流程的初衷,不仅是为了方便收集目前特定用户的性能问题,更重要的是可以收集任何客户反馈的任何问题。
要落实这一系列流程,需要在技术面提供多方面的支持:
- 服务监控系统的更改(前端、后端)
- 数据脱敏(大数据)
- 数据展示(前端)
- 问题实验室(前端、BFF)
最终,经过几轮测试,问题被清晰的定位:
- HTTP1.1协议效率低下的问题
- 队头阻塞
- 头部臃肿
- 大量的JS代码重复
- 大量JS代码无差别加载
- 大量的API网络请求
措施的制定与实施
针对HTTP1.1的优化措施
队头阻塞问题
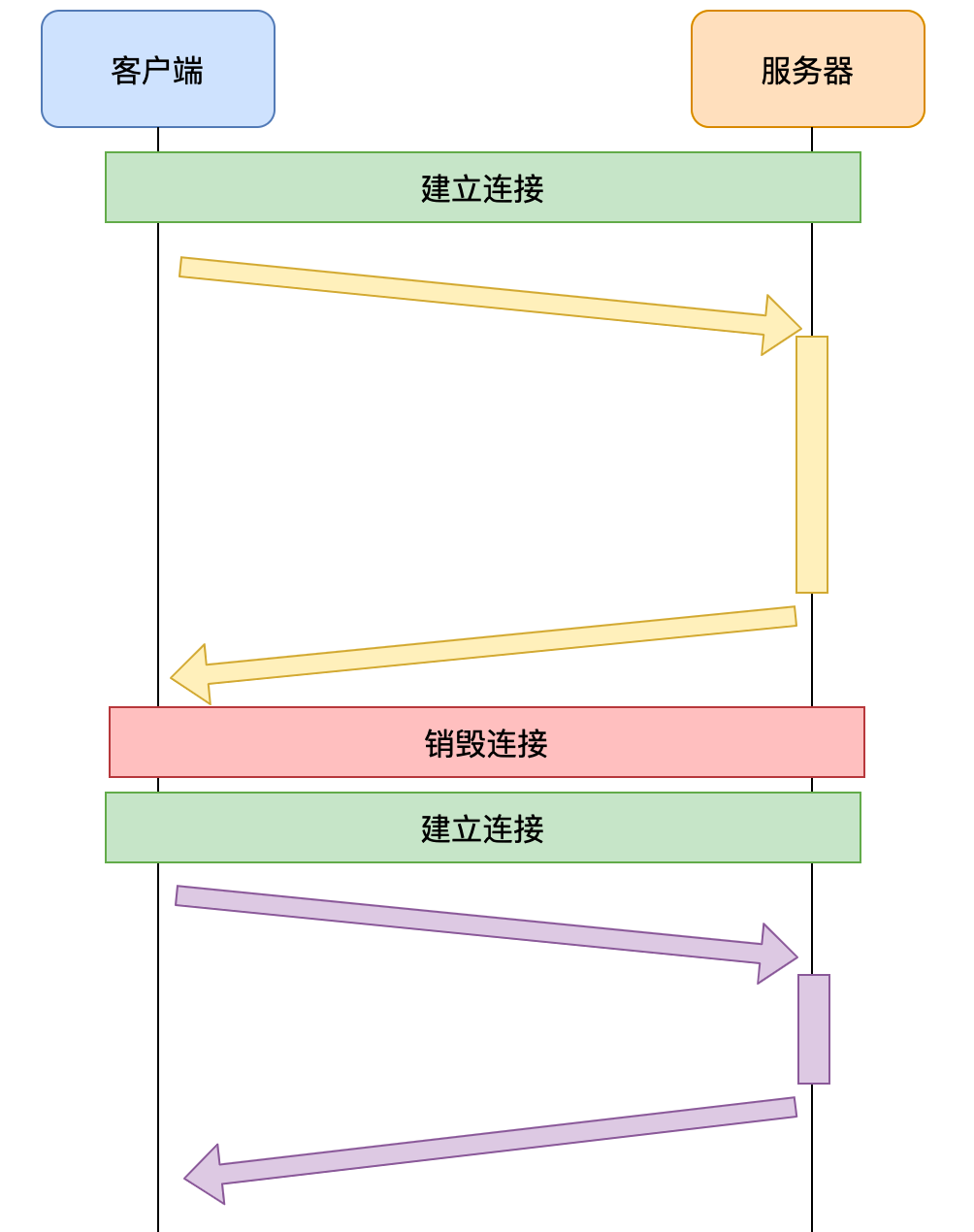
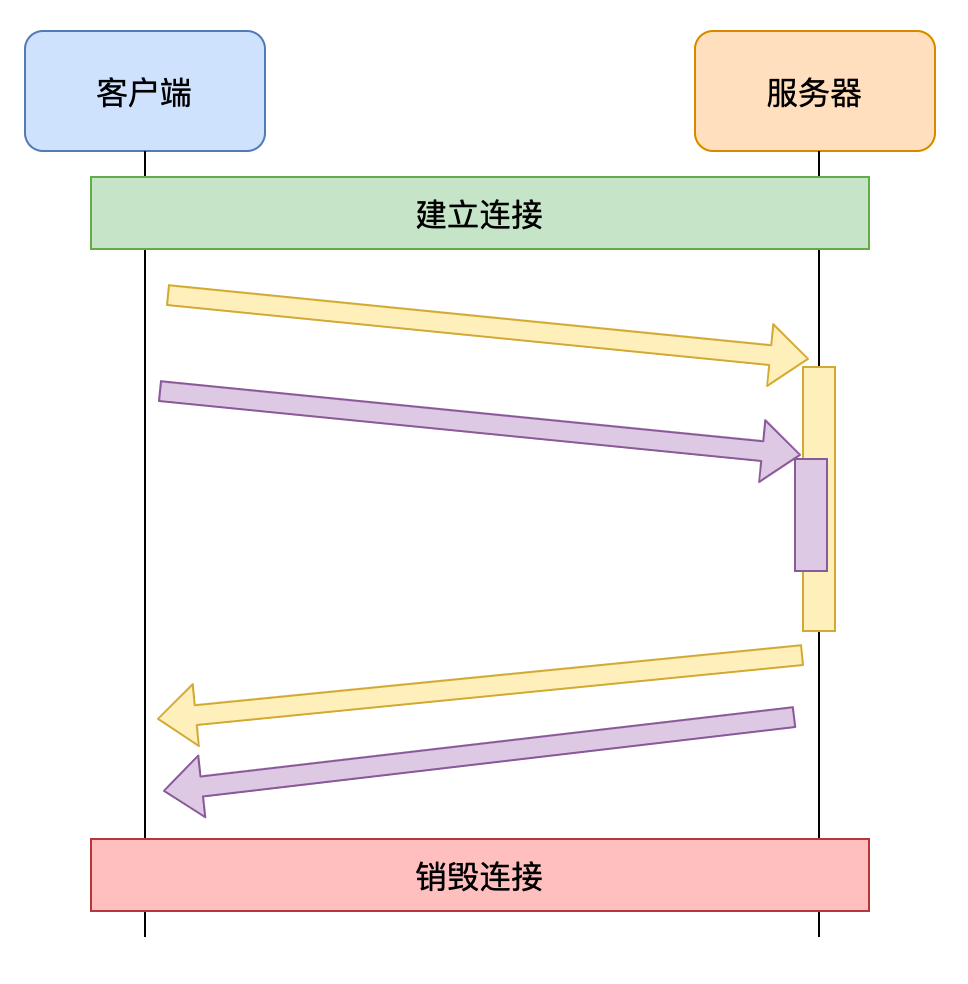
针对这一问题,没有别的办法,只能多开域名来解决。
浏览器针对同一域名可以支持最多6个TCP并发连接,超越这个数字后将发生队头阻塞


头部臃肿
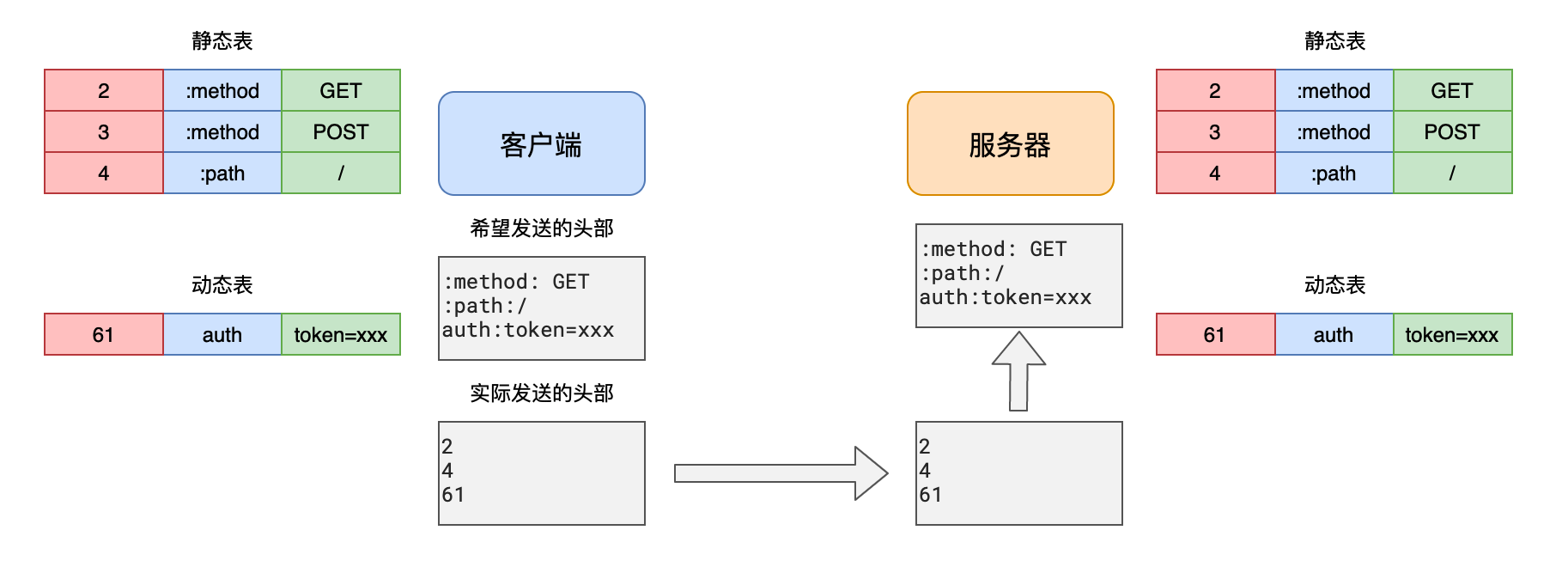
由于HTTP1.1不支持头部压缩,而发送的请求中包含大量的自定义头部,于是我们借鉴了HTTP2的头部压缩方式,对自定义头部进行了压缩处理。
针对重复代码的优化措施
客户侧会产生巨量的差异化JS文件,每个JS文件的产生逻辑非常简单:

结果就是客户侧保存了大量JS代码文件,并且代码文件中出现了大量重复代码。
// g-d8a65e.js
export default {
formItems: [
{
// 其他差异配置,
init(){
// 代码段a
// 其他差异代码段
},
focus(){
// 代码段a
// 其他差异代码段
}
}
]
}
// g-e218fa.js
export default {
formItems: [
{
// 其他差异配置,
validate(){
// 代码段a
// 其他差异代码段
},
blur(){
// 代码段a
// 其他差异代码段
}
}
]
}比较容易想到的解决办法,是把那些有可能出现差异的代码提取到公共代码中。

这种方案除了逻辑简单,根本无法实施,主要原因是:
- 很难知道客户侧会产生哪些重复代码
- 如果把所有可能都枚举到公共代码中,会产生大量的无效代码
因此,对重复代码的提取必须动态完成。

这里面有两个关键问题:
- 如何找到代码中的重复?
- 何时提重?
如何找到重复?
考虑下面两段代码,如何找到重复?
// 代码片段1
const selectSource = "department";
const source = getData(selectSource);
bindSelectSource({
source,
label: (s)=>`${s.name}`,
value: (s)=>`${s.id}`
});
// 代码片段2
const selectSource = "task";
const source = getData(selectSource);
bindSelectSource({
source,
label: (s)=>`${s.title}`,
value: (s)=>`${s.id}`
});通过AST分析,可以得到两棵树

我们的目标是:找出两棵树连续的相同结构的节点,将它们提取成函数,同时把相同结构中的不同点提取为函数参数。
大致思路是:
- 计算每个节点的结构hash
// 变量声明节点的hash求值
class VariableDeclarationNode {
// ...省略其他代码
hash(){
md5.append(this.kind); // const、var、let
md5.append(this.name); // 变量名
md5.append(this.init.type); // 初始值类型: 字面量、表达式、变量
return md5.end(); // 得到hash
}
}- 将AST树信息入库(含hash结果)
库中的信息大致如下:
[
{
"filename": "1.js",
"struct": [
{
hash: ".....", children: [
{ hash: "....", children:[] },
{ hash: "....", children:[] },
]
},
{
hash: ".....", children: [
{ hash: "....", children:[] },
{ hash: "....", children:[] },
]
}
]
},
{
"filename": "2.js",
"struct": [
{
hash: ".....", children: [
{ hash: "....", children:[] },
{ hash: "....", children:[] },
]
},
{
hash: ".....", children: [
{ hash: "....", children:[] },
{ hash: "....", children:[] },
]
}
]
}
]- 寻找库中出现的连续的、hash一致的节点进行提重。
- 将差异点提取为参数
最终提重的结果如下:
// repeating.js
// 自动提重后的代码
function rp_2d4ef(p1, p2){
const selectSource = p1;
const source = getData(selectSource);
bindSelectSource({
source,
label: (s)=>`${s[p2]}`,
value: (s)=>`${s.id}`
});
}然后代码片段被修改为:
// 代码片段1
rp_2d4ef("department", "name");
// 代码片段2
rp_2d4ef("task", "title");何时提重?
为了保证效率,提重可以异步延时执行,也可以开启计划任务在服务器空闲时执行,也可以管理员手动执行。
针对无差别加载的优化措施
过去,用户侧自定义产生的差异JS都是在首屏全部加载的,实际上,很多JS并不需要在当前页面运行。
因此,需要对这些JS进行差别化加载,视口内需要的先加载,不需要的延迟加载。
这就需要做到两件事:
- 定义每个功能页视口内组件
- 标识每个JS文件对应到哪个组件(已有功能)
此时很容易完成,不再详细阐述。
针对大量API网络请求的优化措施
大量的首屏请求均来自自动化生成的差异代码,其中包含大量的GET重复请求。
我们针对性的加入了短时缓存,让相同的请求走缓存通道。
// 自动生成的代码
const data = await getSelectSource('department')
// 修改为
const data = await withCache(getSelectSource, 'department');let map = new Map();
function withCache(fn, ...args){
if(!map){
return fn(...args);
}
let caches = map.get(fn);
if(!caches){
// 无缓存,初始化
map.set(fn, caches = []);
}
let cache = caches.find(c=>isSameArgs(args, c.args)); // 按参数查找缓存
if(!cache){
// 无缓存,初始化
caches.push(cache = {
args,
value: fn(...args)
})
}
return cache;
}
const CACHE_DURATION = 5000;
setTimeout(()=>{
map = null;
}, CACHE_DURATION)